Aiven for Valkey™ clustering Limited availability
Aiven for Valkey™ clustering provides a managed, scalable solution for distributed in-memory data storage with built-in high availability and automatic failover capabilities.
Valkey clustering distributes your data across multiple nodes (shards) to handle larger datasets and higher traffic loads than a single-node deployment can support. Each shard contains a portion of your data, and the cluster automatically routes requests to the appropriate shard.
Key features
High availability
- Automatic failover: If a primary node fails, a replica is automatically promoted to maintain service availability.
- Minimal downtime: Designed to handle both expected maintenance and unexpected failures with minimal service interruption.
- Read replicas: Each shard includes at least one read replica for redundancy and improved read performance.
Scalability
- Flexible sizing: Supports various instance sizes, including smaller 4 GB RAM instances for cost optimization.
Compatibility
- Cluster-enabled mode: Fully compatible with existing Valkey and Redis cluster-aware client libraries.
- Standard protocols: If your application currently uses a client for Valkey standalone mode, switch to a cluster-aware client to enable compatibility with Aiven for Valkey clustering.
Architecture overview
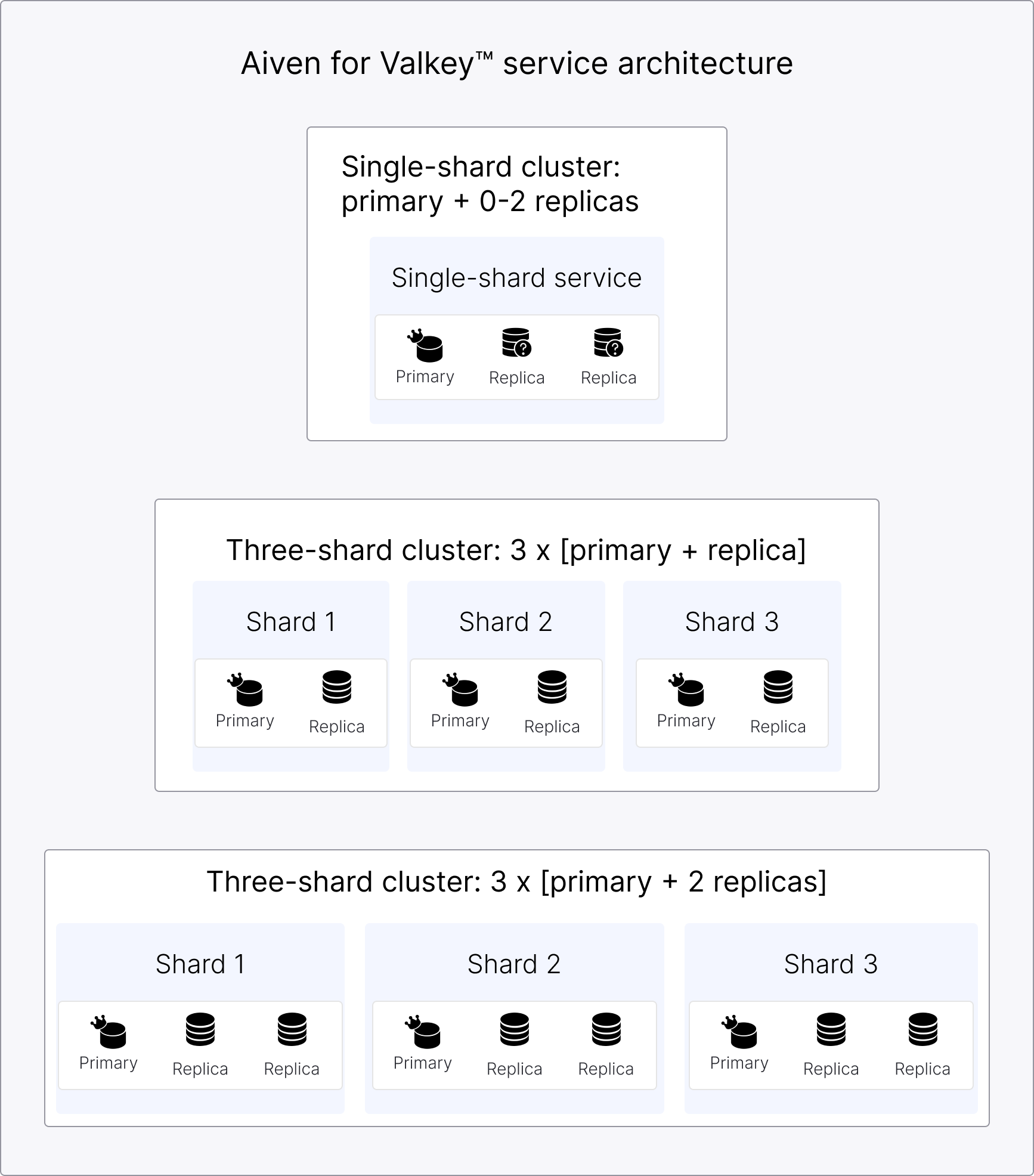
Multi-shard deployment
The typical cluster deployment consists of three primary nodes, each with at least one replica, providing true high availability and scalability.
- Distributed data: Data is automatically partitioned across multiple shards.
- Independent replicas: Each shard has its own set of replicas for redundancy.
- Load distribution: Requests are distributed across shards based on data location.
Single-shard deployment
While Aiven for Valkey supports single-node clusters, this configuration is functionally equivalent to a standalone Valkey instance and is not the primary use case for clustering.
- Initial configuration: Starts with one primary node and 0 - 2 read replicas
- Use case: Ideal for smaller datasets or applications with moderate traffic
- High availability: Automatic failover to replicas if the primary fails
Benefits
Performance
- Higher throughput: Distribute read and write operations across multiple nodes.
- Read scaling: Multiple replicas per shard increase read capacity.
Reliability
- Fault tolerance: Adding replicas for each shard at service creation ensures your service remains available even if individual nodes fail.
- Automatic recovery: Failed nodes are automatically replaced and synchronized.
- Data protection: Multiple copies of your data across different nodes.
Operational simplicity��
- Managed service: Aiven handles cluster setup, maintenance, and scaling.
- Automated operations: Node discovery, failover, and resharding happen automatically.
- Monitoring included: Built-in metrics for performance and health monitoring
Use cases
High-traffic applications
- Applications requiring more throughput than a single node can provide
- Systems with high read/write ratios that benefit from multiple replicas
- Services needing guaranteed uptime despite hardware failures
Large datasets
- Data that exceeds the memory capacity of a single node
- Applications requiring data partitioning for performance optimization
- Systems that need to scale storage capacity
Mission-critical systems
- Applications requiring high availability and automatic failover
- Services that cannot tolerate single points of failure
- Systems with strict uptime requirements
How it works
Plan your deployment
- Assess your requirements: Determine your data size, traffic patterns, and availability needs.
- Choose your configuration: Start with a single shard for smaller workloads or multiple shards for larger datasets.
- Select instance sizes: Choose appropriate memory and compute resources for your workload.
Create a clustered service
To enable clustering in Aiven for Valkey, choose a multi-node cluster plan when creating your service.
For high availability and improved read scalability, add replicas to each service shard during service creation. This allows you to fully leverage the benefits of clustering from the start.
Configure a client
- Ensure your application uses a cluster-aware Valkey/Redis client library. If your application currently uses a client for Valkey standalone mode, switch to a cluster-aware client to enable compatibility with Aiven for Valkey clustering.
- Configure your client to discover and connect to cluster nodes automatically.
- Test failover behavior to ensure your application handles node changes gracefully.
Limitations and considerations
Clustering is supported for new services only.
Current scope
The following are planned for future releases:
- Backup and restore
- Online resharding
- Horizontal scaling
Performance factors
- Network latency between shards can affect cross-shard operations.
- Resharding operations may temporarily impact performance.
- Client library choice can affect cluster performance and behavior.
Related pages